If we assume that the community of listeners grow with each episode, a direct comparison of download numbers actually is not valid since every new episode will have a slightly bigger number of downloads than the previous ones.
So how can we then measure if an episodes performs better or worse than other episodes?
I assumed the following:
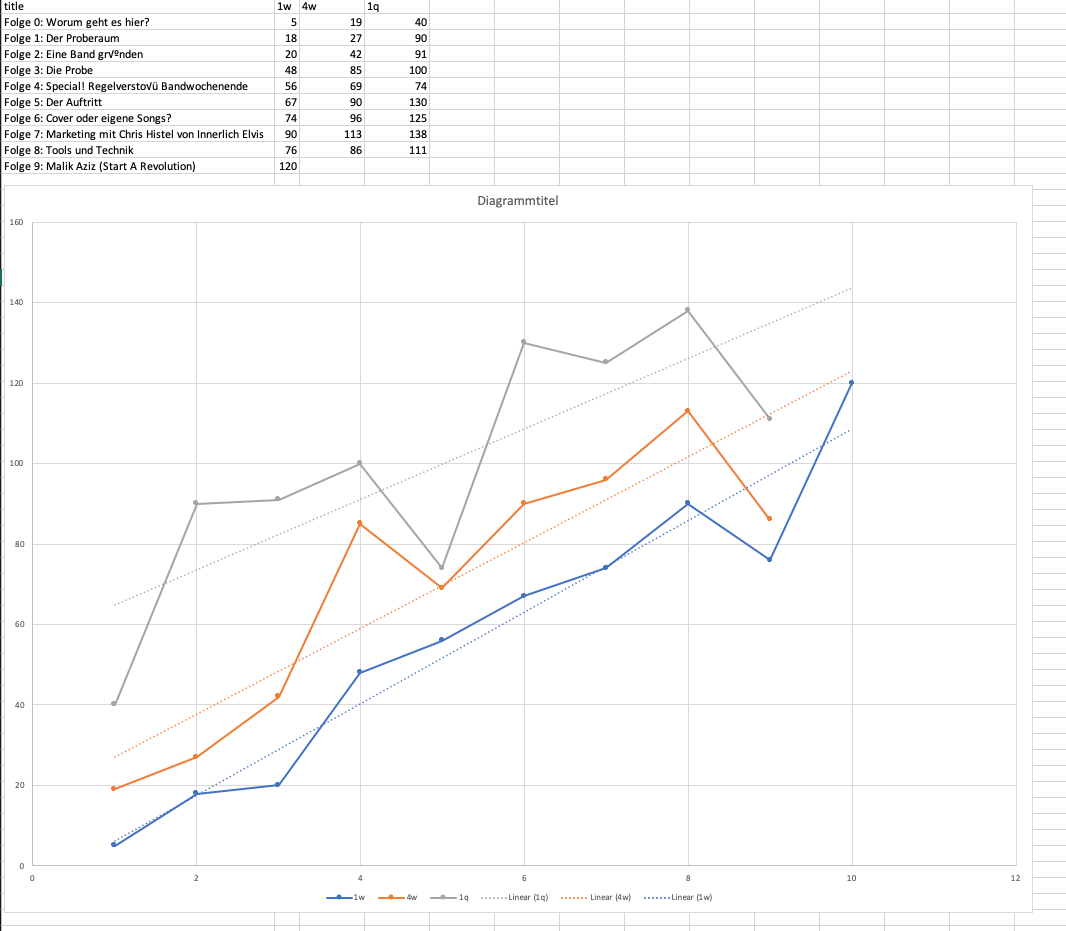
Given that you publish on a (more or less) regular basis with a continuous quality of content I assume that the number of listeners grows linearly. Given that we can calculate a linear regression over all episodes’ downloads at the same given time after publication.
The deviation of the regression then shows how a specific episode performs.
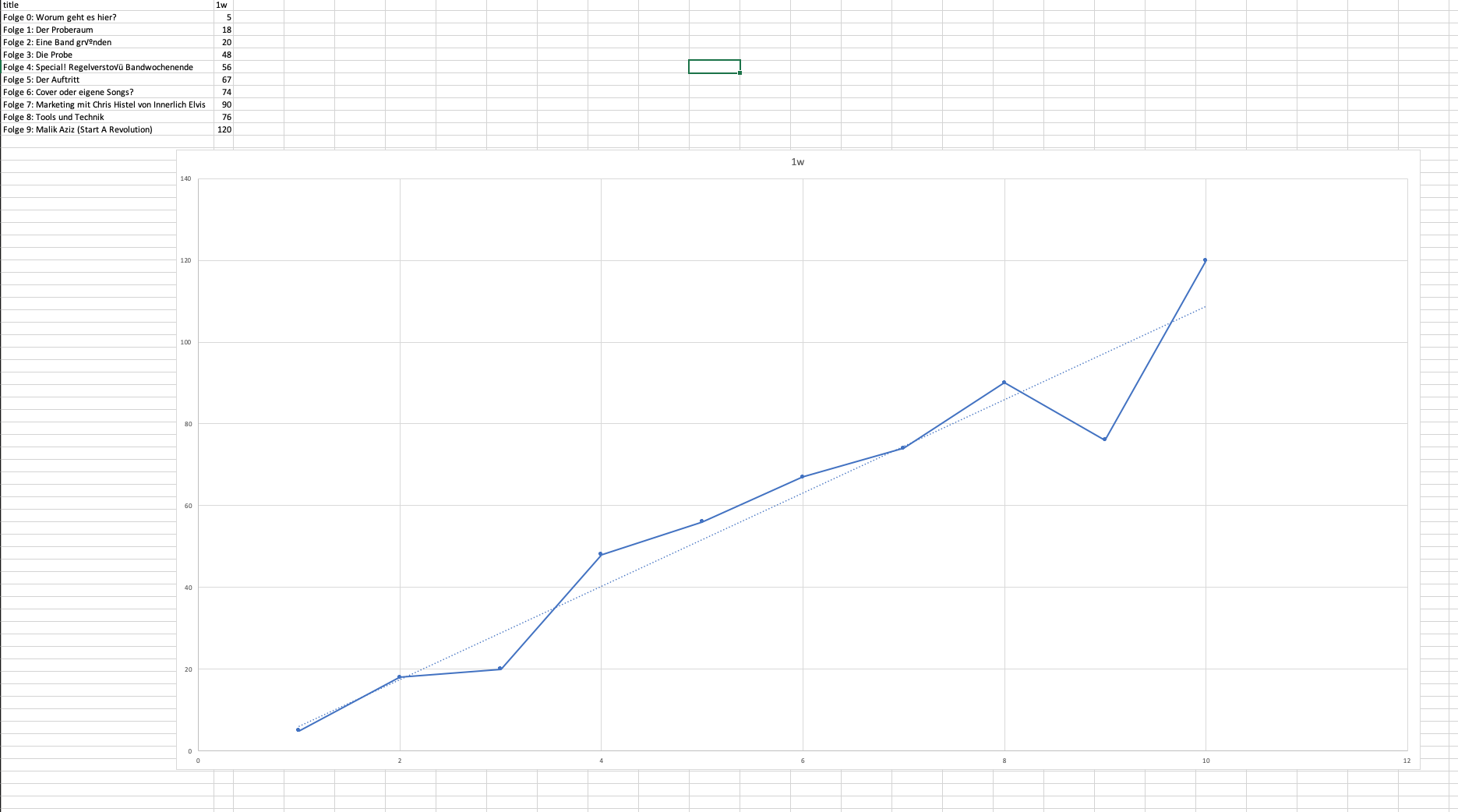
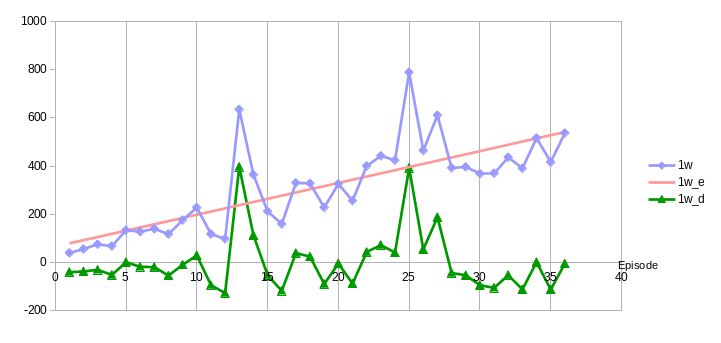
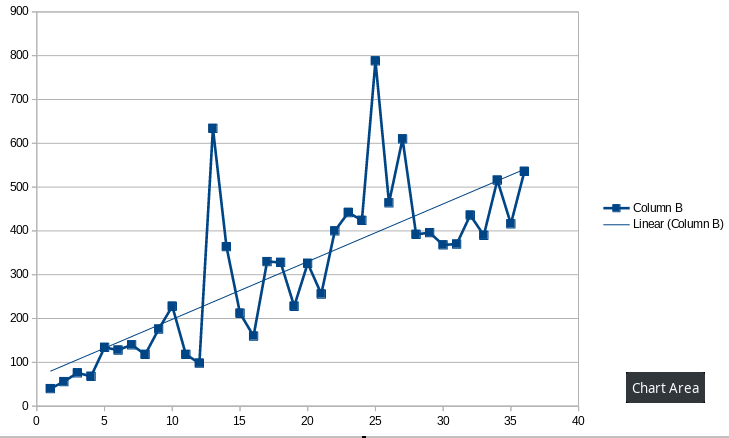
Have a look at the diagram: the x-axis is the episode number, on the left side the 1st episode, on the right side episode 36. The y-axis shows the number of downloads. The blue line is the number of downloads per episode after 1 week (1w) and the red line is the linear regression of it.
As we can see – even without regression line – the line on average increases with every new episode.
The green line shows the difference between the actual value and the predication of the regression. If a number is above 0 it performs better than the average and if it is less than 0 it performs worse.
In the diagram we can see that e.g. episodes 13 and 25 had exceptional high downloads. This would have been obvious even without this diagram. But we can also see that e.g. episodes 9 and 10 performed much better than episodes 19 and 21 although the absolute download numbers of 19 and 21 are greater than those of 9 and 10.
I made this diagram with Libreoffice Spreadsheet which is pretty easy.
What do you think about my assumptions? Did I overlook something or does it make sense to you?
Would it make sense to implement this into the online analytics?
Best regards,
Bernhard
 )
)